|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| A neural radiance field (NeRF) is a scene model supporting high-quality view synthesis, optimized per scene. In this paper, we explore enabling user editing of a category-level NeRF - also known as a conditional radiance field - trained on a shape category. Specifically, we introduce a method for propagating coarse 2D user scribbles to the 3D space, to modify the color or shape of a local region. First, we propose a conditional radiance field that incorporates new modular network components, including a shape branch that is shared across object instances. Observing multiple instances of the same category, our model learns underlying part semantics without any supervision, thereby allowing the propagation of coarse 2D user scribbles to the entire 3D region (e.g., chair seat). Next, we propose a hybrid network update strategy that targets specific network components, which balances efficiency and accuracy. During user interaction, we formulate an optimization problem that both satisfies the user's constraints and preserves the original object structure. We demonstrate our approach on various editing tasks over three shape datasets and show that it outperforms prior neural editing approaches. Finally, we edit the appearance and shape of a real photograph and show that the edit propagates to extrapolated novel views. |
|
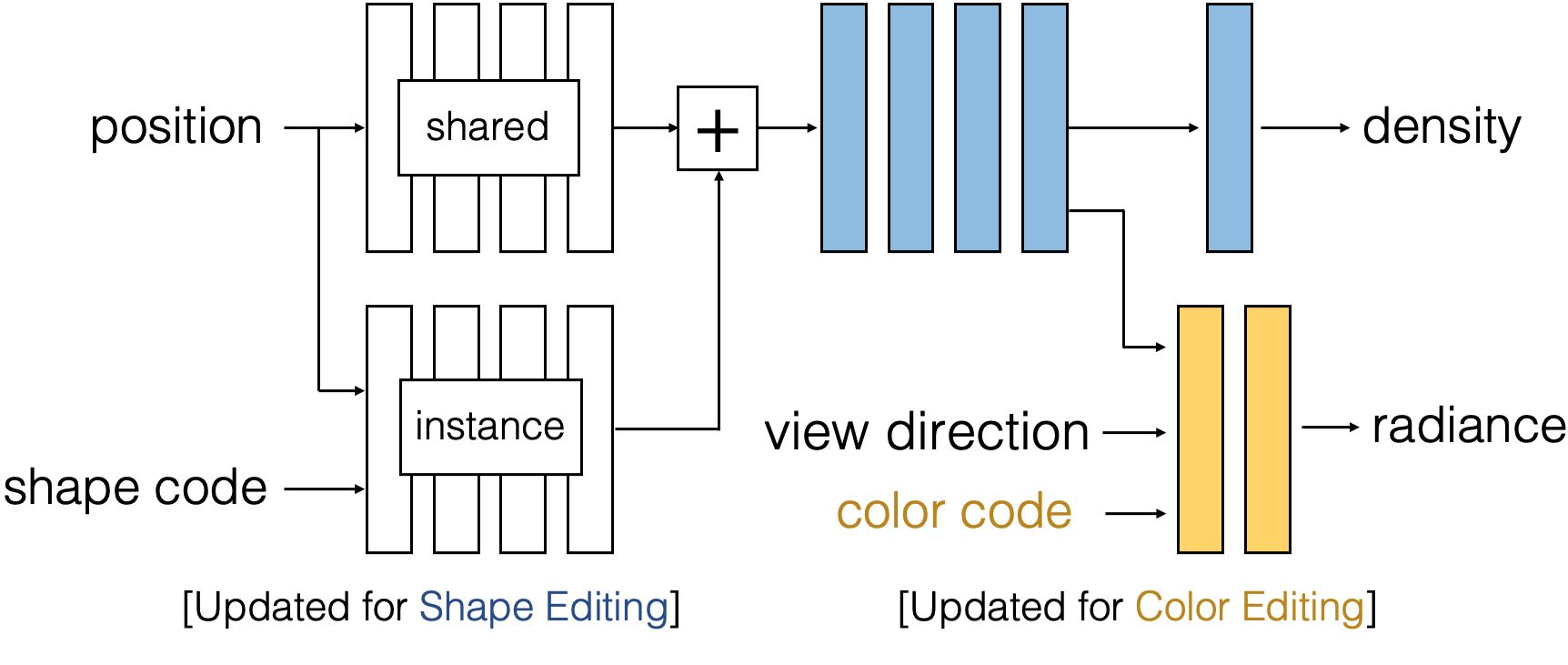
| To propagate sparse 2D user scribbles to novel views, we learn a rich prior of plausible-looking objects by training a single radiance field over several object instances. Our architecture builds on NeRF in two ways. First, we introduce shape and color codes for each instance, allowing a single radiance field to represent multiple object instances. Second, we introduce an instance independent shape branch, which learns a generic representation of the object category. Due to our modular architecture design, only a few components of our network need to be modified during editing to effectively execute the user edit. |

|
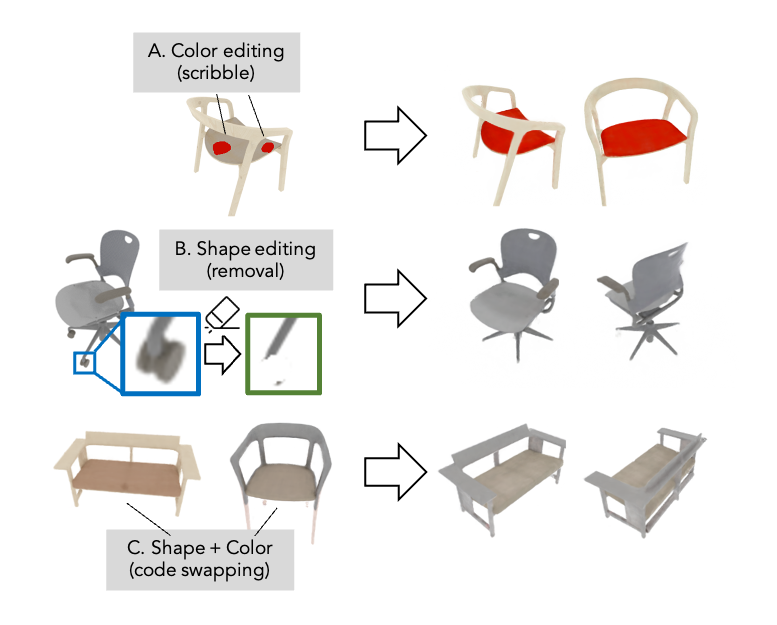
| Our method propagates sparse 2D user scribbles to fill an object region, rendering the edit consistently across views. The user provides a color, a foreground scribble for the region to change, and a background scribble for regions to keep unchanged. To conduct the edit, we optimize a reconstruction-based loss to encourage the model to change the color at the foreground scribble, but maintain the color on the background scribbles. |

|
| Our method propagates 2D user edits to remove or add an object part, propagating the 2D edit consistently across views. For shape removal, the user scribbles over a region of the object to remove. To conduct the removal, we optimize both a reconstruction loss and a density-based loss, encouraging the model to remove density at the scribbled regions. For shape addition, the user selects an object part to paste into the instance. To conduct the addition, we optimize a reconstruction loss similar to the one used for color editing. |

|
| Our method can transfer shape and color between object instances simply by swapping the color and shape codes between instances. Though the color output of the model is functionally dependent on the shape code, we observe that changing the shape code leaves the color of the chair unchanged. |

|
| Our method can finetune a conditional radiance field to a single still real image. Our method is able to render novel views of the real object instance and conduct color and shape editing on the instance. |
 |
S. Liu, X. Zhang, Z. Zhang, R. Zhang, J. Y. Zhu, B. Russell. Editing Conditional Radiance Fields. (hosted on ArXiv) |
Acknowledgements |